



AMD新一代APU正式版产品全面详测
或许您已经看过国内一些有关AMD Kaveri新一代APU的评测文章。但我们要告诉您的是,很遗憾,您看过的几乎国内所有Kaveri APU评测都没能展示它的大创新之处——对异构运算的优化。在此之前,几乎所有的国内媒体在对Kaveri APU的测试上都存在重大的缺失——您还不知道怎样才能真正实现Kaveri的统一内存寻址功能,您还从未体验过实现统一内存寻址后,那迅疾如风的异构运算处理速度。不用遗憾,今天《微型计算机》评测室将带给您为全面的AMD新一代APU正式版产品详细评测。

在本次评测中,我们将采用面向零售市场的Kaveri APU正式版产品进行测试。同时,我们还获得了在BIOS上专为Kaveri APU进行优化的首批A88X主板,以及性能强劲的AMD Radeon内存,从而能得到非常准确的测试结果。此外,我们还拥有详尽的配套软件、驱动,以及技术指导文档,因此可以对Kaveri APU进行全面、深度的测试。当然,在测试开始之前,还是让我们首先回顾一下AMD新一代APU Kaveri的主要技术特性(详细技术分析文章可参见2013年9月上)。
对于AMD来说,Kaveri APU是自APU诞生以来非常重要的一款产品。它不仅对处理器核心进行了大幅更新,引入统一内存寻址架构设计,其整合图形核心、生产工艺也获得了全面的升级,可以说它几乎是一款全新设计的产品。为此Kaveri APU也成为AMD为重视,IT业界为关注,DIY玩家为期待的一款产品,从技术上来看,它主要做了以下几大创新。
第一款采用统一内存寻址架构的APU
与以往APU相比,Kaveri是真正第一款将CPU和GPU放在同等地位的APU,其具体特征就是Kaveri APU采用了统一内存寻址(简称为hUMA)架构设计。在进行通用运算时,传统的CPU+GPU的分离式架构通过PCI-E总线调配CPU和GPU中的数据,并且CPU和GPU各自又拥有本地存储设备,这就造成了两者之间数据的共享和传输存在巨大的延迟,降低了通用运算的性能。而在Kaveri APU上采用的hUMA设计,则使得CPU和GPU能够使用统一的内存与缓存空间,数据存放于CPU和GPU公共的空间中,可以被CPU和GPU同时调用和读取,完全没有任何带宽和数据存储上的阻隔。CPU与GPU不仅可以高效地访问、分享、传输数据,保持数据一致性,还可按任务特性灵活地将工作分解给CPU与GPU,使它们同时以大性能完成任务。其效率相比传统的CPU+GPU分离式设计有了翻天覆地般的提升,同时也为异构计算本身的发展打开了大门。
×4核心×每周期每核心8次计算+GPU频率(720MHz)×512个流处理单元×每周期每个流处理器单元2次计算=855.68GFLOPS。")
Kavrei APU中CPU与GPU的异构运算能力高可达到856GFLOPS,其计算方法为:CPU频率(3.7GHz)×4核心×每周期每核心8次计算+GPU频率(720MHz)×512个流处理单元×每周期每个流处理器单元2次计算=855.68GFLOPS。
。但在新一代工艺的帮助下,Kaveri核心内集成了多达24.1亿个晶体管,而Richland只有13.03亿个。")
尽管核心面积大小差不多(Kaveri为245mm2,Richland为246mm2)。但在新一代工艺的帮助下,Kaveri核心内集成了多达24.1亿个晶体管,而Richland只有13.03亿个。
继承R9 290独立显卡主要技术特性
同时,Kaveri为吸引眼球的就是采用了由R9 290独立显卡改进而来的Radeon R7整合显示核心,其GPU部分从之前的VLIW升级到了GCN架构,具有更快的渲染速度。而在规格方面,Kaveri APU也有所提升。其A10系列的高规格产品内部集成了8个CU单元,每个CU单元有64个流处理单元,这样Kaveri APU就拥有512个流处理单元。功能方面,新的Kaveri APU不仅完美支持DirectX 11.2、OpenGL 4.3,也支持AMD独有的Mantle API、TureAudio音频等新技术。其中后者在APU内集成了一个专门用来处理声音、改善音效的DSP数字信号处理器,可以减少约10%的CPU占用率。
更智能的电源管理
不只是性能,Kaveri APU也带来了更好的能效比。它拥有更加智能的电源管理器,可以根据程序应用需求,对处理器内的CPU与GPU计算单元进行彻底关闭、唤醒、全速启动等多种状态的智能管理,使得APU对能耗的控制更加精准、高效。同时,得益于28nm SHP超高性能生产工艺的采用,APU芯片内部对芯片漏电的控制将更加到位,其设计TDP较以往APU也有所降低。
除了以上三大进步,Kaveri APU还为CPU核心采用了效率更高的“B类压路机架构”,相比同档次的推土机和打桩机架构,其综合性能提升了大约15%~20%。整体来看,Kaveri APU获得了非常全面的进化。
Kaveri APU正式版及配套测试平台产品赏析
参与本次测试的A10-7850K是AMD新一代APU中,目前定位高的产品。其内部的Radeon R7整合显示核心集成了8个CU单元,每个CU单元有64个流处理单元,这样A10-7850K就拥有多达512个流处理单元。同时,这款APU对高频内存提供了优秀的支持度,DDR3 2400内存在A10-7850K上也可轻松运行,这为进一步提升APU整合3D性能创造了条件。而在处理器核心上,由于它采用了同频性能更好的压路机架构设计,因此尽管上一代Richland APU的顶级产品A10-6800K,默认CPU频率高达4.1GHz,Boost频率高达4.4GHz。但Kaveri APU顶级产品A10-7850K的频率却有所降低,其默认工作频率为3.7GHz,Boost频率为4.0GHz,大概低了10%左右。
华擎FM2A88X极限玩家6+是首批在BIOS上对Kaveri系列APU提供支持的FM2+A88X主板。它采用了豪华的8(处理器核心)+2(显示核心)相供电设计,可以充分发挥出Kaveri APU强大的超频能力。功能方面,该主板板载了两颗TI NE5532运放芯片,其中一颗在前置音频线路中起耳放作用,可驱动大600欧的高端耳机;另一颗则用于后置音频的差分线路,可以起到提升音质减小噪音的作用。同时,主板还拥有XFast LAN极速网络调节、X-Boost一键超频等功能。
“AMD是目前业内唯——个可以提供CPU、GPU、主板芯片组三大组件的半导体公司。”如果您对AMD的认识还停留在这一句话,那可就落伍了。早在2011年底,AMD就正式进军内存市场。AMD内存产品分为三个档次,分别是娱乐级(Enter tainment Edition)、性能级(Per formance Edition)和发烧级(Radeon Edition)。而本次为Kaveri APU搭配的就是其顶级内存产品Radeon DDR3 2400。要想在APU上实现DDR3 2400的工作频率也很简单,只要在BIOS中的内存频率选项里选中相应的超频预设档案,内存就会进行自动超频。
AMD A10-7850K 产品资料
CPU核心/线程数 4/4 L2缓存容量 4MB 整合显示核心规模 512个流处理器 CPU Boost频率/基准频率(GHz) 4.0/3.7 GPU Boost频率/基准频率(MHz) 720/654 超频支持 支持 内存频率(MHz) DDR3 2400 TDP(W) 95
华擎FM2A88X极限玩家 6+产品资料
接口 FM2+
板型 ATX
供电设计 8+2相
内存插槽 DDR3×4
显卡插槽 PCI-E 3.0 x16×1 PCI-E 3.0 x8×1 PCI-E 2.0 x4×1
扩展插槽 PCI-E 2.0 x1 ×2 PCI×2
音频芯片 瑞昱ALC1150 Codec7.1声道
网络芯片 高通创锐讯AR8171千兆网卡

AMD RADEON DDR3 2400游戏内存产品资料
接口类型 DDR3 240 Pin
内存容量 单根4GB×2
内存电压 1.65V(DDR3 2400)
默认时序 11-12-12-30@DDR3 2400
13-13-13-32@DDR3 1866
11-11-11-29@DDR3 1676

我们如何测试
测试目的:本次测试为重要的目的,当然是了解在采用统一内存寻址架构后,Kaveri APU在通用运算应用中,是否能拥有比其他APU、CPU更加优秀的表现。同时此次测试还将重点了解在采用GCN架构的Radeon R7整合显示核心后,Kaveri APU将带来怎样的3D性能。此外,我们也将关注在CPU频率降低,采用更先进的压路机架构后,是否能保证Kaveri APU具备与上一代Richland APU相当甚至更好的CPU性能。后,我们还将测试Kaveri APU的功耗、发热量与超频能力,看看28nm生产工艺是否给我们带来了惊喜。
测试平台
处理器 AMD A10-7850K AMD A10-6800K
英特尔Core i5 4670K(Haswell)
主板 华擎FM2A88X 极限玩家 6+
技嘉G1.Sniper Z87
显卡 AMD Radeon R7整合显示核心 AMD Radeon HD8670D 整合显示核心 Intel HD Graphics 4600核芯显卡 GeForce GT 630显卡
内存 AMD Radeon DDR3 2400 4GB×2
硬盘 日立DK7SAF400 Deskstar 4TB机械硬盘 OCZ Vertex 4 512GB SSD
电源 X7-1200
操作系统 Windows7 Ultimate 64bit
”这一新设备")
设备管理器里首次出现了“AMD HSA(with WDDM)”这一新设备

使用特别的版本后,Corel AfterShot Pro的硬件加速选项由普通的显示核心变为“AMD HSA DEVICE”。
开启统一内存寻址架构 独家解锁异构运算功能
我们在文章开头已经说到,统一内存寻址架构可以大大提升APU在通用运算中的效率。不过要享受到这一架构的优势,除了硬件上的必要设计外,还需要驱动与软件的配合。简单地说,我们需安装必要的HSA异构运算驱动,同时软件厂商也需要使用AMD的专用开发工具,对其软件进行相应地优化、转换(无需重新建立编程模型)才能让用户享受到统一内存寻址架构带来的高速运算效果。而正是这两大必要条件的存在,也使得各位在国内几乎所有Kaveri APU评测上,体验不到统一内存寻址架构的优势——因为他们的测试没有满足任一条件。
下面,我们就以COREL AfterShot Pro数码照片处理软件为例,向大家简要说明如何在这一软件里体验到Kaveri统一内存寻址架构的优势。第一步,当然是安装AMD的显卡驱动。接下来,我们需要在与显卡设备相关的注册表里添加一个名为“KMD_EnableHsa”的32bit DWORD值,并将值设为“1”。保存重启后,我们会发现在设备管理器里多出一个名为“AMD HSA”的新设备,这时就需要用户通过设备属性界面,手动安装其特别的HSA异构运算驱动。安装完成后,惊叹号消失,设备名更新为“AMD HSA(with WDDM)”,显示这一设备已完成驱动装载。然后,我们还需要为处理器的“IOMMU”(输入输出内存管理单元)手动安装新驱动。值得注意的是,IOMMU设备由于以往主要用于专业的虚拟机,因此在很多家用主板BIOS里是默认关闭的,需在BIOS开启后,才能在设备管理器找到它。
在完成硬件设备的驱动安装后,我们还需要在注册表里添加一组特殊的32bit DWORD值,并安装为统一内存寻址架构优化的OpenCL运行库。接下来,还需用户修改环境变量,通过命令提示符发出相关指令,才算正式完成“统一内存寻址架构”的硬件驱动安装。不过,我们还需要对Corel AfterShot Pro的软件做出相应地更新。在普通版本里,打开Corel AfterShot Pro的硬件加速选项后,设备里显示的加速设备始终是APU的显示核心,而在更新其特别的1.2.0.6版本后,硬件加速设备则变为“AMD HSA DEVICE”。这显示出,软件也终于为统一内存寻址架构做好了准备。
综合来看,由于统一内存寻址架构目前还处在不断发展、不断测试的阶段,因此要让一些应用软件享受到它的技术优势,还暂时需要用户进行较为繁琐的设置。后期,AMD将大大简化安装流程一一键安装将成为现实。那么,在完成硬件与软件的准备后,统一内存寻址架构的引入到底能为我们带来怎样的惊喜呢?
效率大幅提升 统一内存架构应用体验
Corel AfterShot Pro图片处理
AfterShot Pro是由加拿大Corel公司推出的一种非常流行的数码照片管理和处理的应用软件。在这个体验中,我们将25张RAW格式照片转换为JPEG格式,并在转换的同时,对所有照片对比度进行调整。测试中,我们将记录完成这整个工作的耗时。 而测试结果令人非常惊讶,A10-7850K Kaveri APU平台的耗时总计仅8.14s,只有Core i5 4670K平台的约1/2。给人的感觉是,Kaveri APU完成这个工作似乎就在眨眼之间。显然,统一内存架构的应用的确大大提升了APU的通用运算效率。
libreOffice金融模型运算体验
libreOffice是一款开源的免费办公软件,它不仅具备文本、表格绘图、EXCEL电子表格等常用功能,还对OpenCL通用运算、AMD统一内存寻址架构进行了很好的支持。测试中,我们使用了美国彭博通讯社制作的一个金融模型,进行循环的宏迭代运算。结果同样令人惊喜,A10-7850K Kaveri APU完成一次宏迭代的运算时间仅281ms,只有AMD A10-6800K平台所用时间的35%。英特尔平台方面,由于核芯显卡尚未对该软件的OpenCL加速进行良好的优化,因此,我们只能完全使用CPU进行运算,而其耗时就高达近1500ms。
JPEG图片解码速度体验
对摄影爱好者来说,打开多张超高分辨率图片一直是一个负载高、耗时长,让人头疼的工作。而在这个应用中,我们将打开24张由尼康D800单反相机拍摄的超高分辨率照片,每一张照片的分辨率高达11986×8000。KaveriAPU在测试中,同样占尽先机,只需4.87s,A10-7850K就完成解码,并打开了所有图片,而分离式架构设计的CPU A10- 6800K则得花费9.39s,Core i5 4670K的所用时间更突破了10s。
测试点评:以上就是目前AMD明确表明对统一内存寻址架构已提供完全优化、支持的三大主要应用。不难发现,新架构的采用的确极大提升了APU的通用运算性能,给APU带来了质的飞跃。那么在其他一些通用运算应用中,Kaveri APU是否还能带来类似的效果呢?

只需约8s的时间,Kaveri APU就在AfterShot Pro里完成了所有图片的格式转换与处理工作。


即便在libreOffice办公软件里进行普通的方程式运算,也能享受到统一内存寻址架构带来的优势。



统一内存寻址架构的采用,让打开JPEG图片这一看似简单的应用也获得了大幅加速。
依然保持领先 其他通用运算应用体验
测试点评:
可以看到,在SiSoftware Sandra的通用运算性能、财务分析、加密解密测试中,Kaveri APU拥有很大的领先幅度。这不仅预示着新版本的评测软件也极有可能对统一内存寻址架构进行了充分优化,而且也再次展现了新架构所拥有的巨大潜力。而在另一个“矿工”们关注的莱特币挖矿计算能力体验中,A10-7850K、A10-6800K相对于核芯显卡、NVIDIA低端独立显卡也有较大的领先幅度。A10-7850K整合显示核心的算力已经突破90khash/s,达到甚至超越不少中低端独显的水平。显然,对于“矿工”来说,采用基于Kaveri APU的平台来挖矿,可以进一步提升收益。
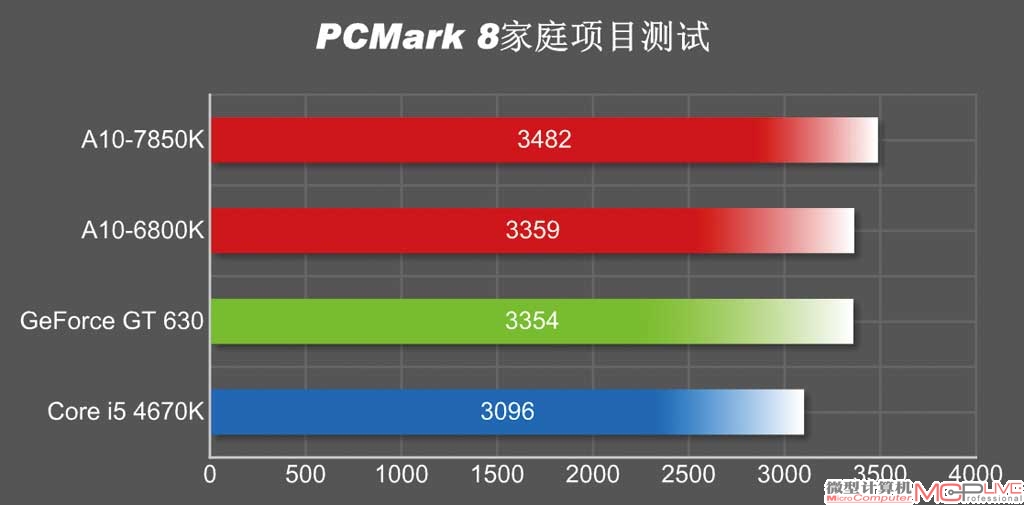
而在那些针对分离式架构APU、CPU设计的软件中,Kaveri APU相对于Richland APU的领先幅度有所减小,但仍有明显的优势。如在反映平台多媒体内容创作、游戏性能的PCMark 8测试中,Kaveri APU相对A10-6800K有近14%的领先,其GIMP动作模糊特效处理速度与A10-6800K相比快了约36%。这些结果显示出,Kaveri APU的整合图形核心、CPU核心显然也经过了明显的改进。








可运行主流大作 3D性能体验
测试点评:
整合图形核心测试上,拥有512个流处理器的A10-7850K轻松击败了包括英特尔核芯显卡、GeForce GT 630在内的所有对手。其中在3DMark、《尘埃:决战》游戏中,A10-7850K给我们带来了较大的惊喜,它的性能速较A10-6800K获得了16%~32%的增幅,可在全高清分辨率、较高画质下流畅运行《使命召唤:幽灵》的表现,显示出Radeon R7系列整合显示核心具备较高的性能;而在其他测试里,如《孤岛危机3》、《古墓丽影9》、《暗黑破坏神Ⅲ》中,A10-7850K也全面领先于A10- 6800K,只是幅度有所缩小而已。
总体来看,A10-7850K拥有目前在台式机里3D性能为强劲的整合显示核心,已完全超越像GeForce GT 630这样的低端独立显卡,具备在较高画质下流畅运行《尘埃:决战》、《使命召唤:幽灵》、《暗黑破坏神Ⅲ》这些主流3D游戏大作的能力。当然,如果想畅玩孤岛危机3》、《孤岛惊魂3》这些硬件杀手,那么用户还是需要购买AMD的高性能独立显卡。原因很简单,尽管A10-7850K的整合图形核心的规格已与Radeon HD 7750相当,但在显存性能上,它与这些高性能独立显卡仍有较大差距。








低频不低能 CPU性能体验
测试点评:
压路机架构显然为Kaveri APU交上了一份让人满意的答卷,尽管默认频率与加速频率都低于A10-6800K,但在这6大CPU测试中,A10-7850K都获得了全胜。其中,在多线程性能测试中,Kaveri APU相对于Richland有大约5%~6%的领先幅度。而在反映单核心性能的Super Pi一百万运算测试中,A10-7850K则获得了约22%的较大提升幅度。






带来更高能耗比 功耗与温度测试
测试点评:
不难看出,尽管在待机状态下,A10-7850K与A10- 6800K的功耗与CPU热裕量(与CPU过热保护温度的相差值,数值越大越好)都非常接近。但在满载状态下,A10-7850K相对于A10- 6800K有非常大的优势,其平台系统功耗比后者低了约25W,CPU温度热裕量也高了约10℃。再结合其优秀的性能表现,A10-7850K APU显然拥有更好的能耗比,其智能的电源管理器与28nm生产工艺功不可没。



对于普通用户来说,更为实用的是进行CPU核心与整合图形核心的双双小幅超频,从而获得娱乐性能上的提升。

如单单仅对CPU核心频率超频,那么APU频率可以在风冷环境下实现4.7GHz的高频,将Super Pi一百万位测试时间缩短至15.647s。


AMD OVERDRIVE超频软件提供了丰富的超频、调节选项,让玩家在操作系统下,就可对APU各项频率与内存小参进行细致地调节。
轻松突破4.7GHz KaveriAPU超频能力体验
更为先进的生产工艺也为Kaveri APU带来了另外一个让人意外的天赋——极强的超频能力。在Kaveri APU上,AMD依然为玩家配套附送了AMDOVERDRIVE超频软件。该软件不仅有非常详细的监控功能,还拥有丰富的频率、电压调节功能,让玩家在Windows操作系统下,就可实时对APU与内存的频率进行调节。而Kaveri APU的超频能力也的确没让人失望。在风冷散热环境下,以往采用32nm生产工艺的APU一般高可以超频到4.5GHz,而在A10-7850K上,如使用1.5V左右的核心电压,则可将APU送上4.7GHz的高频,并完成Super Pi一百万位运算,将运算时间缩短到仅15.647s。当然,若想在超频后,完成CINEBENCH R11.5这样的多线程渲染测试,则需降低频率与电压,否则CPU温度会触发其过热保护机制导致降频。经我们测试,A10-7850K可在1.35V核心电压下,以4.3GHz的频率完成CINEBENCH R11.5 CPU渲染测试,令AMD APU也能取得突破4pts的成绩。
不过我们认为,对普通用户来说,更有意义的是进行“双超”——即对CPU频率、整合图形核心频率进行同步超频,从而获得娱乐性能上的提升。从体验来看,在进行“双超”时,由于提升显示核心频率与电压会增加APU的发热量,因此需进一步降低CPU核心的超频幅度。终我们在CPU核心频率为4.1GHz(核心电压1.3V)、整合显示核心频率1028MHz时取得了平衡。在此设置下,A10-7850K可以较为稳定地运行,而其娱乐性能也得到了切实的提高。3DMark Fire Strike测试成绩达到1662分,提升幅度近13%。
惊喜才刚刚拉开帷幕
综合以上测试,我们认为AMD新一代APU Kaveri圆满地履行了它的诞生使命。无论是功耗、整合3D性能,还是CPU性能、超频能力,它的各项表现较以往的APU产品都有明显的提升。而在对统一内存寻址架构进行优化的通用运算应用里,Kaveri APU更获得了质的飞跃,以往A PU的性能表现往往多只能达到Kaveri APU的50%。同时,Kaveri APU在这些应用里也可以轻松地将Intel Core i5这种传统架构设计的高性能CPU远远甩在身后。显然,采用统一内存寻址架构设计对于APU的发展来说是一条非常正确的道路,对于AMD而言,剩下的工作就是简化HSA驱动安装方法,加强对软件厂商的攻势,帮助它们学习掌握在统一内存寻址架构下的软件编程及改进,推出更多为新架构设计、更新的软件,让统一内存寻址架构渗透到Photoshop、OFFICE等常用应用中去。待相关应用增多时,APU必将改变人们以往只重视CPU同构运算性能的习惯,从而获得另一次类似“干掉Pentium 4”的胜利。


{kind=link}
{kind=link}